Meso-Economics là gì?
Meso-Economics (Kinh tế học trung mô) là cách tiếp cận nghiên cứu nền kinh tế ở cấp độ trung gian, nằm giữa vi mô (microeconomics) và vĩ mô (macroeconomics). Trọng tâm của meso-economics không phải là quyết định của từng cá nhân riêng lẻ, cũng không phải là các đại lượng tổng hợp toàn nền kinh tế, mà là các cấu trúc, tổ chức, mạng lưới và thể chế nơi hành vi vi mô được điều phối, khuếch đại và chuyển hóa thành kết quả vĩ mô.
Nói cách khác, meso-economics trả lời câu hỏi:
Các quyết định cá nhân được kết nối với nhau như thế nào để tạo ra các động lực và kết quả ở quy mô hệ thống?

Vì sao cần đến Meso-Economics?
Phân tích kinh tế truyền thống thường gặp một “khoảng trống” giữa vi mô và vĩ mô:
- Vi mô mô tả tốt động cơ và lựa chọn cá nhân, nhưng khó giải thích hiện tượng tập thể (đổi mới lan tỏa, khủng hoảng chuỗi cung ứng, hiệu ứng mạng).
- Vĩ mô mô tả được bức tranh tổng thể, nhưng thường giả định cơ chế liên kết từ vi mô, thay vì phân tích trực tiếp các cơ chế đó.
Meso-economics xuất hiện để lấp đầy khoảng trống này bằng cách đưa các cấu trúc trung gian—ngành, chuỗi giá trị, cụm, nền tảng, mạng lưới—trở thành đối tượng phân tích trung tâm.
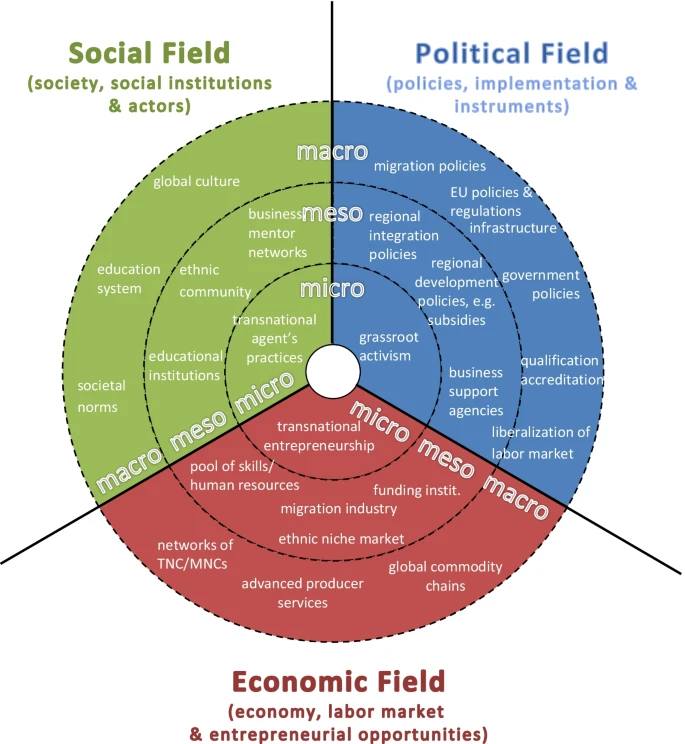
Đối tượng và phạm vi nghiên cứu của Meso-Economics
Ở cấp trung mô, các đối tượng nghiên cứu điển hình bao gồm:
- Ngành và cấu trúc ngành: mức độ tập trung, cạnh tranh, đổi mới, tiêu chuẩn.
- Chuỗi giá trị và chuỗi cung ứng: phân công lao động, nút nghẽn, khả năng chống chịu.
- Cụm ngành (clusters) và vùng kinh tế: lợi thế tập trung, học hỏi lan tỏa.
- Hệ sinh thái kinh doanh: mối quan hệ giữa doanh nghiệp, nền tảng, nhà cung cấp, người dùng.
- Thể chế trung gian: hiệp hội ngành nghề, cơ quan điều tiết, tiêu chuẩn kỹ thuật.
- Mạng lưới kinh tế – xã hội: hiệu ứng mạng, lan truyền công nghệ, thông tin và hành vi.
Những cấu trúc này không phải là “bối cảnh thụ động”, mà là tác nhân định hình hành vi.
Các câu hỏi cốt lõi của Meso-Economics
Meso-economics tập trung trả lời các câu hỏi như:
- Hành vi cá nhân được điều phối thông qua cấu trúc nào?
- Thể chế và tiêu chuẩn giới hạn hoặc mở rộng lựa chọn ra sao?
- Đổi mới và công nghệ lan tỏa qua những kênh nào?
- Vì sao chính sách giống nhau lại cho kết quả khác nhau giữa các ngành hay địa phương?
- Những cú sốc (dịch bệnh, khủng hoảng tài chính, biến đổi khí hậu) khuếch đại như thế nào qua chuỗi cung ứng và mạng lưới?
Nền tảng lý thuyết và phương pháp
Meso-economics mang tính liên ngành và sử dụng đa dạng công cụ:
- Kinh tế học thể chế và tiến hóa: vai trò của luật lệ, chuẩn mực, học hỏi.
- Phân tích mạng lưới (network analysis)
- Mô hình tác nhân (Agent-Based Models): mô phỏng tương tác cục bộ tạo ra hành vi hệ thống.
- Phân tích chuỗi giá trị và input–output cấp ngành.
- Phương pháp so sánh điển hình (comparative case studies).
Điểm chung của các phương pháp này là không giản lược hệ thống về các tác nhân độc lập.

Meso-Economics và chính sách công
Meso-economics đặc biệt hữu ích trong thiết kế và đánh giá chính sách, bởi vì:
- Chính sách thường tác động thông qua cấu trúc trung gian, không trực tiếp đến từng cá nhân.
- Các chính sách công nghiệp, chuyển đổi năng lượng, chuyển đổi số, phát triển vùng đều có bản chất trung mô.
- Phân tích meso giúp tránh tư duy “một chính sách cho tất cả”, thay vào đó là thiết kế theo ngành, theo cụm, theo hệ sinh thái.
Quan hệ với Micro-, Macro- và Meta-Economics
Có thể hình dung ba cấp độ phân tích như sau:
- Micro-economics: tập trung vào ai ra quyết định và vì sao.
- Meso-economics: phân tích bằng cách nào các quyết định đó được kết nối và điều phối.
- Macro-economics: quan sát điều gì xảy ra ở cấp tổng thể.
Trong khi đó, meta-economics đứng ở tầng phản tư, đặt câu hỏi về các giả định và phương pháp của cả ba cấp độ. Meso-economics vì vậy vừa là cầu nối thực nghiệm, vừa là nơi thử nghiệm các khung tư duy mới (như kinh tế học phức hợp hay kinh tế học lượng tử).
Nói tóm lại, meso-Economics không thay thế vi mô hay vĩ mô, mà bổ sung một tầng phân tích thiết yếu để hiểu nền kinh tế như một hệ thống tổ chức và quan hệ. Trong bối cảnh các thách thức hiện đại—bất ổn chuỗi cung ứng, chuyển đổi xanh, chuyển đổi số—meso-economics cung cấp một lăng kính giúp kết nối hành vi cá nhân với kết quả hệ thống một cách thực tế và giàu thông tin hơn.
Tài liệu tham khảo và đọc thêm
- https://inomics.com/blog/mesoeconomics-missing-link-or-needless-pedantry-1544457
- https://www.weforum.org/stories/2012/10/the-new-economics-meso-and-meta/
- https://zero100.com/mesoeconomics-a-data-centric-approach-to-supply-chain-strategy/
- https://econfix.wordpress.com/2024/06/06/mesoeconomics-what-is-it-and-why-is-it-important/
- https://www.project-syndicate.org/onpoint/mesoeconomics-study-of-networks-supply-chains-key-to-successful-industrial-policies-by-william-h-janeway-2024-05



















.jpg)




