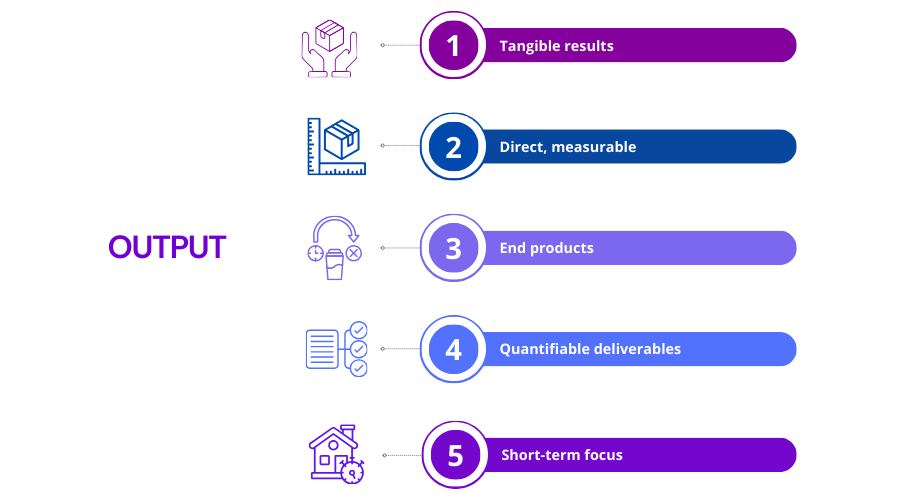
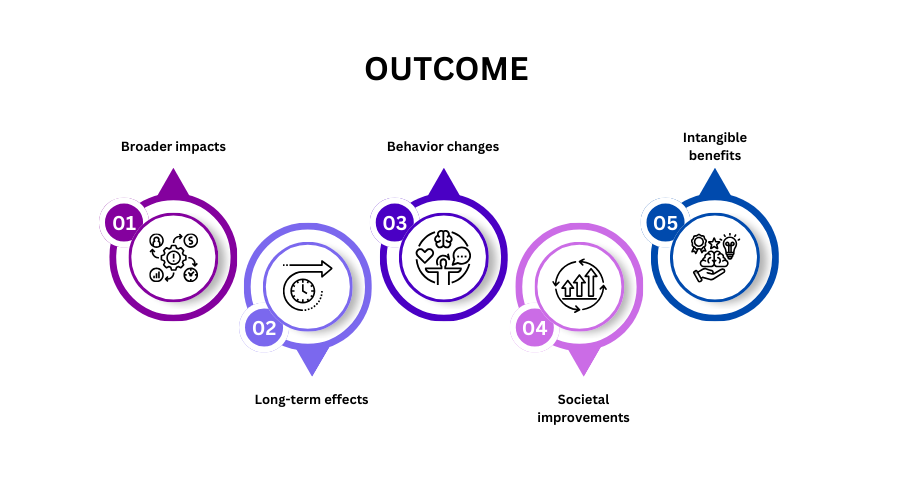
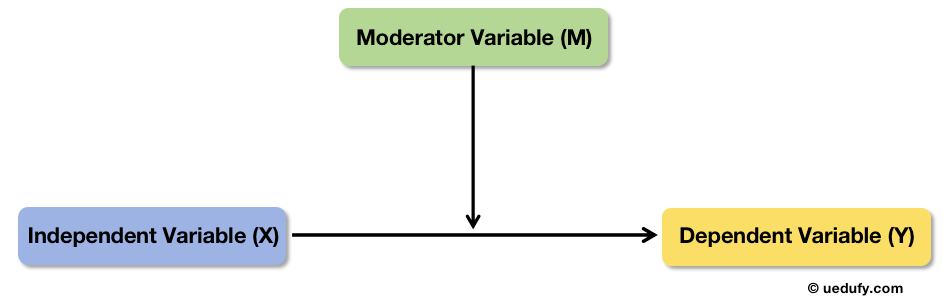
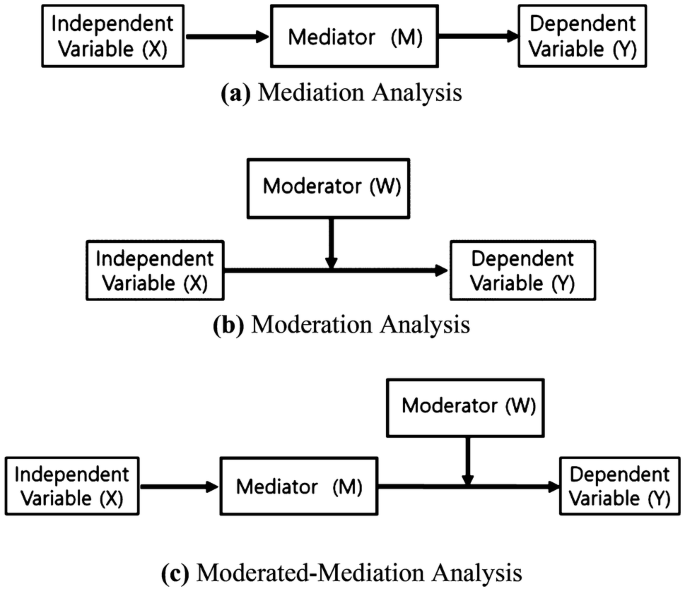
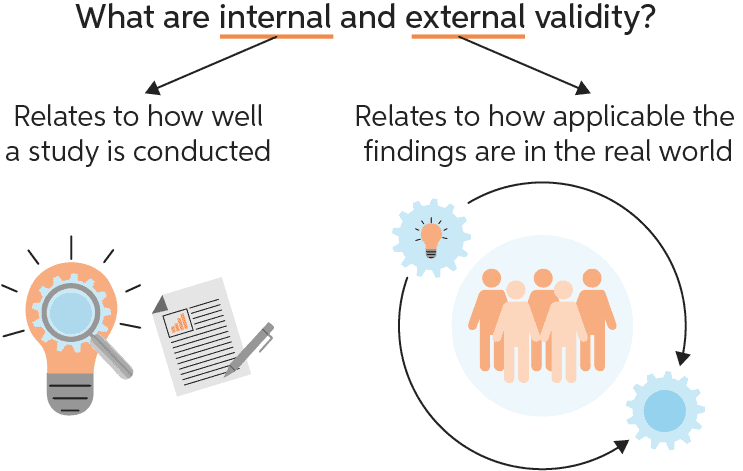
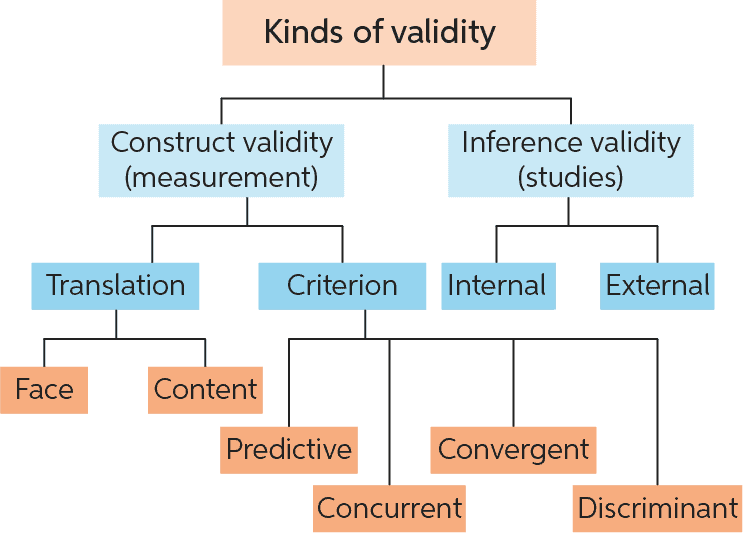
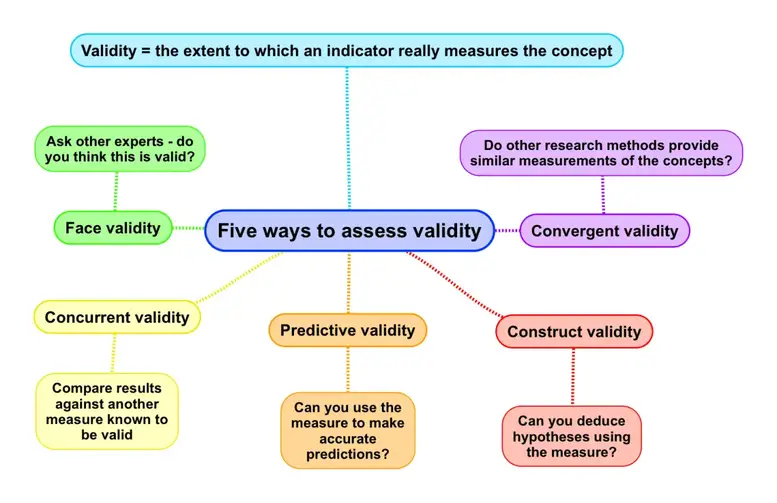
(Nguồn: https://www.researchgate.net/profile/Nicholas-Steneck/publication)
Research ethics provides guidelines for the responsible conduct of research. In addition, it educates and monitors scientists conducting research to ensure a high ethical standard. The following is a general summary of some ethical principles:
Honesty (Trung thực):
Honestly report data, results, methods and procedures, and publication status. Do not fabricate, falsify, or misrepresent data.
Objectivity (Khách quan):
Strive to avoid bias in experimental design, data analysis, data interpretation, peer review, personnel decisions, grant writing, expert testimony, and other aspects of research.
Integrity (Chính trực):
Keep your promises and agreements; act with sincerity; strive for consistency of thought and action.
Carefulness (Cẩn trọng):
Avoid careless errors and negligence; carefully and critically examine your own work and the work of your peers. Keep good records of research activities.
Openness (Cởi mở):
Share data, results, ideas, tools, resources. Be open to criticism and new ideas.
Respect for Intellectual Property (Tôn trọng quyền sở hữu trí tuệ):
Honor patents, copyrights, and other forms of intellectual property. Do not use unpublished data, methods, or results without permission. Give credit where credit is due. Never plagiarize.
Confidentiality (Bảo mật):
Protect confidential communications, such as papers or grants submitted for publication, personnel records, trade or military secrets, and patient records.
Responsible Publication (Công bố có trách nhiệm):
Publish in order to advance research and scholarship, not to advance just your own career. Avoid wasteful and duplicative publication.
Responsible Mentoring (Hướng dẫn có trách nhiệm):
Help to educate, mentor, and advise students. Promote their welfare and allow them to make their own decisions.
Respect for Colleagues (Tôn trọng đồng nghiệp):
Respect your colleagues and treat them fairly.
Social Responsibility (Trách nhiệm xã hội):
Strive to promote social good and prevent or mitigate social harms through research, public education, and advocacy.
Non-Discrimination (Không phân biệt đối xử):
Avoid discrimination against colleagues or students on the basis of sex, race, ethnicity, or other factors that are not related to their scientific competence and integrity.
Competence (Năng lực):
Maintain and improve your own professional competence and expertise through lifelong education and learning; take steps to promote competence in science as a whole.
Legality (Tính hợp pháp):
Know and obey relevant laws and institutional and governmental policies.
Animal Care (Chăm sóc động vật):
Show proper respect and care for animals when using them in research. Do not conduct unnecessary or poorly designed animal experiments.
Human Subjects Protection (Bảo vệ con người):
When conducting research on human subjects, minimize harms and risks and maximize benefits; respect human dignity, privacy, and autonomy.
(Nguồn: https://www.enago.com/academy/wp-content/uploads/2023/12/WhyResearchEthicsMatter.png)
Nguồn tham khảo
- https://libguides.library.cityu.edu.hk/researchmethods/ethics